背景
最近发现其中一套生产环境的MySQL集群主从数据同步延迟问题严重,从库积累了很多中继日志,导致分配数据库磁盘使用率超过90%告警。这问题从排查到处理过程耗费了很长时间,在这里记录下整个处理过程,希望能给其他遇到此类问题的朋友一点帮助。
先介绍下环境情况,这套MySQL集群使用的k8s容器化部署,使用的三节点MySQL MGR复制模式,数据存储使用的ceph rbd块存储
– MySQL版本:8.0.19
– Ceph版本:12.2.10(Luminous)
排查
最早发现主从数据库之间很多表数据不同步,MGR集群状态正常
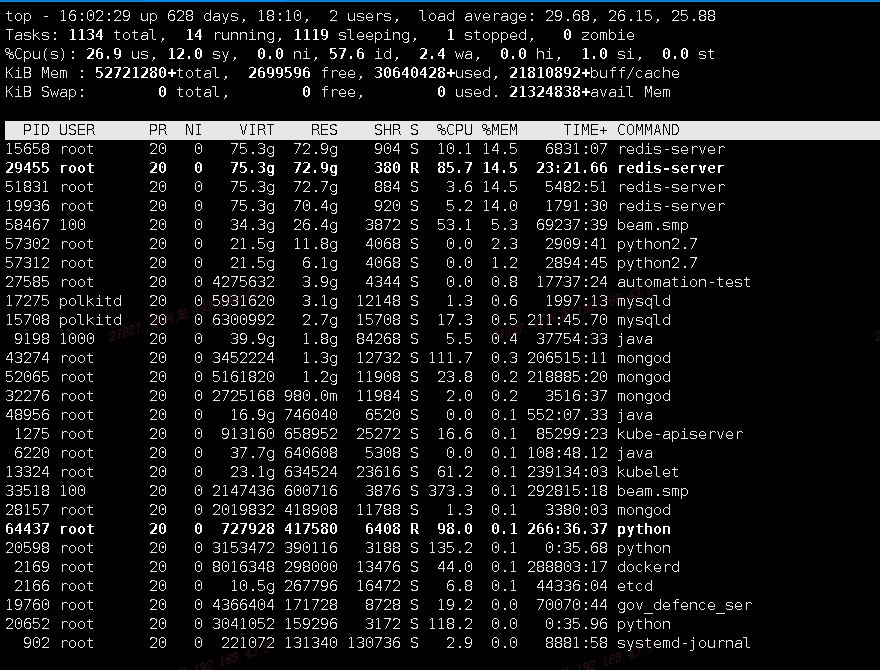
检查操作系统负载情况
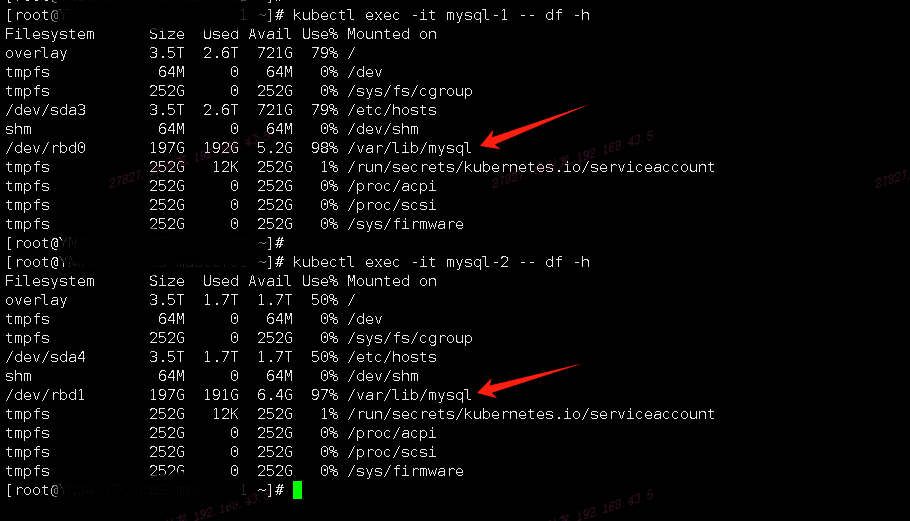
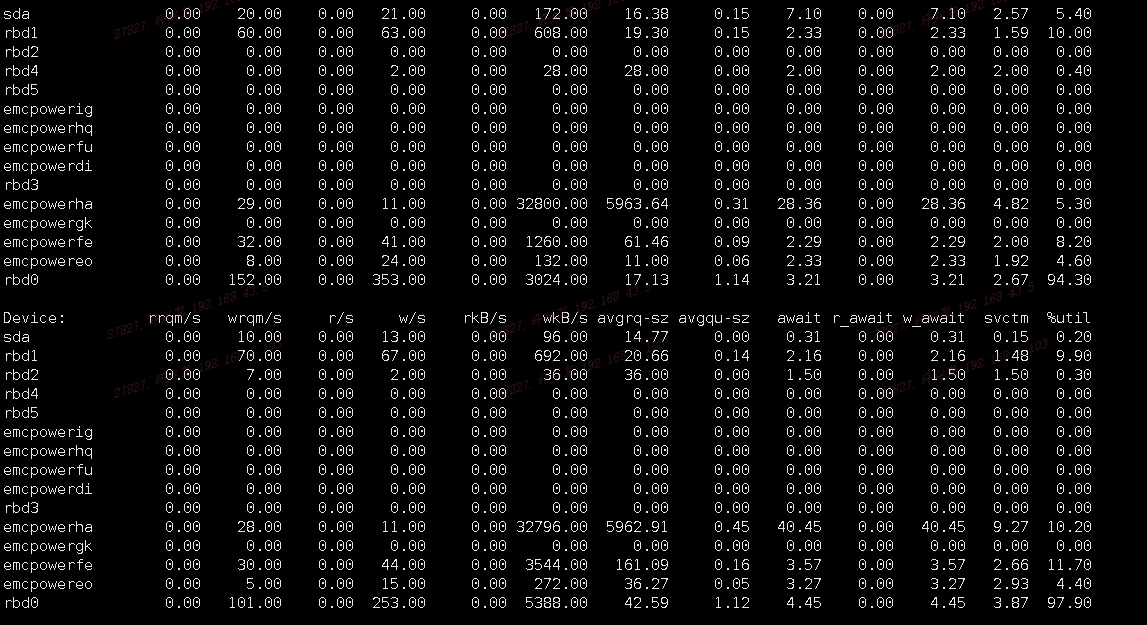
从库MySQL磁盘挂载(rbd0)IO情况,看到rbd0磁盘%util超过90%一直处在繁忙状态
查看防火墙规则,没什么限制
通过主库建立测试库操作来验证主从同步延迟情况,在test测试库下删除t2表
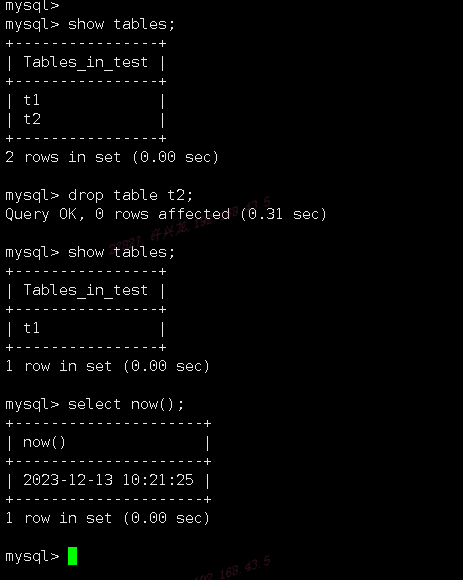
从库查看test库下表情况,半小时过去后从库t2表依然未删除,从库事务执行差距很大,查询过事务队列在堆积
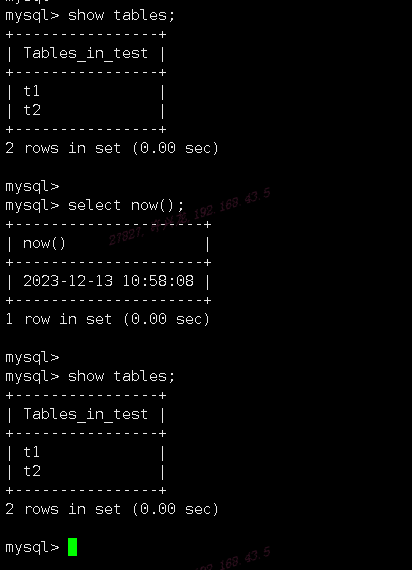

中继日志积压一大堆未完成,导致从库磁盘使用率超过90%爆满